")
")
Platform T: a robust and flexible technology for Twitter analysis
 We created the Platform T to perform a robust, flexible and customizable analysis of Twitter content. Platform T is based upon several scripts mainly designed by Rodrigo Travitzki comprising the following computer implementations:
We created the Platform T to perform a robust, flexible and customizable analysis of Twitter content. Platform T is based upon several scripts mainly designed by Rodrigo Travitzki comprising the following computer implementations:
- PHP (dynamic internet);
- MySQL (database);
- R (statistical analysis).
The scripts work as a plug-in to the GNU/GPL software YourTwapperKeeper and have been widely tested on UNIX systems (Linux and Mac OS).
Platform T collects, compares and tabulates Twitter data providing some basic exploratory analysis of each sample (tweets clustered by a keyword or hashtag). Platform T thus produces a variety of objects - tables, matrices and networks - that can subsequently be used for different uses and objectives.
What follows next is a diagram of the Platform T structure. It depicts the diversity of Twitter APIs used to cluster the required data and the general connection over Twitter, PHP, MySQL and R.
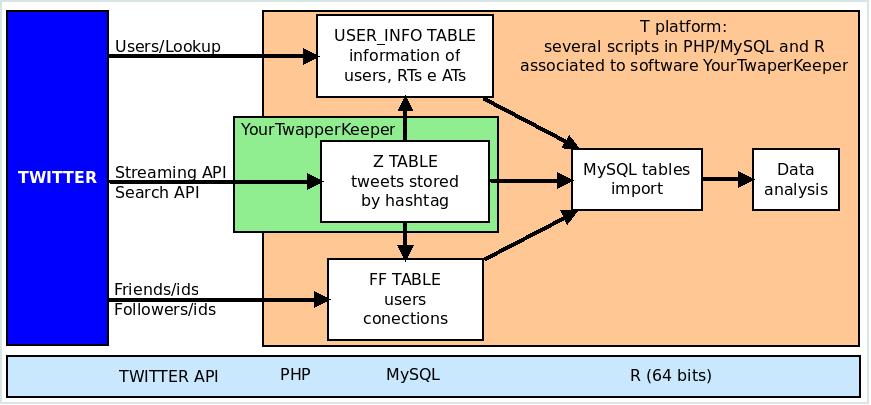
Twitter API
Twitter is still divided into three different API - Application Programming Interfaces (namely Streaming, Search and Rest API) that are not fully compatible with one another. The Search API is currently the most important API for statistical analysis, followed by the Streaming API.
The search API is called with a REST URL that can be retrieved with a simple HTTP Get request, and nearly all Twitter monitoring tools depend on this API. We have worked on a widely revised version of YourTwapperKeeper, a tool for archiving tweets, in order to integrate these three APIs into one single Platform.
The collected data include basic information about the users and the messages (tweets) and the full network of users and messages clustered along the given hashtag. This data is necessary in order to map the network topology created by the tag.
Twitter API and the Issue 214
We have worked on a series of scripts that make three extra calls per requests on Twitter API so that we can retrieve all the required social data for the network topology and get around the few quirks and incompatibilities Twitter has regarding the results of Search and Rest API (Issue 214).
This happens because the field "from_user_id" returned from the Search API does not match the correct Twitter user_id, which is isusually retrieved from the Rest API. This forces a manual lookup of the user_id via the Rest API in order to fix this API bug known as Issue 214.
Our platform is connected to the Twitter Streaming API and makes calls to the Twitter Rest API and Twitter Search APIs, thus allowing our servers to request the missing data from Twitter Search and Rest APIs and to match up the user with its correct user_id.
Site
![]()
![]()
